// Tutorial //
How to Ensure Cluster Reliability with ChaosMesh on DigitalOcean Kubernetes

Introduction
By itself, Kubernetes strives to provide a resilient and scalable platform for hosting applications and workloads. When faults occur, it automatically tries to repair them to keep the cluster and its deployments in the desired state. While effective, the self-healing ability of the cluster is limited to watching over Pods, which can be too coarse-grained.
ChaosMesh is an open source, Kubernetes native platform for chaos engineering. It allows you to replicate real-world faults, delays and stress tests against the Pods that can occur during development and production. By doing this, you can uncover weak spots in the cluster in a controlled manner and work on resolving them before they actually occur. ChaosMesh scales with the cluster and provides a dashboard for easier chaos orchestration and visualization of fault scenarios.
In this guide, you’ll set up ChaosMesh using Helm. You’ll then use it to inject transient failures into example Hello Kubernetes backend services using kubectl. Then, you’ll expose the ChaosMesh dashboard to get an overview of currently running chaos experiments and create new ones. Finally, you’ll learn how to develop chaos workflows, which introduce status checks to experiments, possibly terminating if they start negatively impacting the deployments.
Prerequisites
-
A DigitalOcean Kubernetes cluster (1.24+) with your connection configured as the
kubectldefault. Instructions on how to configurekubectlare shown under the Connect to your Cluster step when you create your cluster. To create a Kubernetes cluster on DigitalOcean, see Kubernetes Quickstart. -
The Helm package manager installed on your local machine. To do this, complete Step 1 of the How To Install Software on Kubernetes Clusters with the Helm 3 Package Manager tutorial.
-
The Nginx Ingress Controller and Cert-Manager installed on your cluster using Helm in order to expose ChaosMesh dashboard using Ingress Resources. For guidance, follow How to Set Up an Nginx Ingress on DigitalOcean Kubernetes Using Helm.
-
A fully registered domain name to host the ChaosMesh dashboard, pointed at the Load Balancer used by the Nginx Ingress. This tutorial will use
dashboard.your_domainthroughout. You can purchase a domain name on Namecheap, get one for free on Freenom, or use the domain registrar of your choice.
Note: The domain name you use in this tutorial must differ from the ones used in the “How To Set Up an Nginx Ingress on DigitalOcean Kubernetes” prerequisite tutorial.
Step 1: Installing ChaosMesh using Helm
In this step, you’ll add the ChaosMesh repo to Helm and install it to your cluster.
You’ll first need to add the repository containing ChaosMesh to Helm:
-
- helm repo add chaos-mesh https://charts.chaos-mesh.org
-
The output will look similar to this:
[secondary_label Output]
"chaos-mesh" has been added to your repositories
Refresh Helm’s cache to download its contents:
-
- helm repo update
-
Then, create a namespace in your cluster where ChaosMesh will reside, called chaos-mesh:
-
- kubectl create ns chaos-mesh
-
Before installing ChaosMesh to your cluster, you’ll create a file called values.yaml, which will hold the values of parameters that need to be set during install. Create and open it for editing:
-
- nano values.yaml
-
Add the following lines:
[label values.yaml]
chaosDaemon:
runtime: containerd
socketPath: /run/containerd/containerd.sock
Here, you set the chaosDaemon.runtime and chaosDaemon.socketPath parameters to their respective values. This instructs ChaosMesh that your cluster is using containerd as its container runtime, which is the default as of Kubernetes 1.24.
Finally, run the following command to install ChaosMesh to your cluster:
-
- helm install chaos-mesh chaos-mesh/chaos-mesh -n=chaos-mesh -f values.yaml
-
The output will look similar to the following, detailing that ChaosMesh is deployed:
[secondary_label Output]
NAME: chaos-mesh
LAST DEPLOYED: Sat Nov 4 17:16:45 2023
NAMESPACE: chaos-mesh
STATUS: deployed
REVISION: 1
TEST SUITE: None
NOTES:
...
You can verify that the chaos-mesh namespace of your cluster now holds the deployed pods:
-
- kubectl get pods -n chaos-mesh -w
-
[secondary_label Output]
NAME READY STATUS RESTARTS AGE
chaos-controller-manager-5979ccc996-929wl 1/1 Running 0 66s
chaos-controller-manager-5979ccc996-kt695 1/1 Running 0 66s
chaos-controller-manager-5979ccc996-xjdwz 1/1 Running 0 66s
chaos-daemon-724l4 1/1 Running 0 66s
chaos-daemon-q8zcv 1/1 Running 0 66s
chaos-dashboard-77f5cf9985-zdcwq 1/1 Running 0 66s
chaos-dns-server-779499656c-wgqj4 1/1 Running 0 66s
You’ve installed ChaosMesh to your Kubernetes cluster. You’ll now learn about chaos experiments, what they are and how to create them.
Step 2: Defining and Running a Chaos Experiment Using kubectl
In this step, you’ll learn about different types of chaos experiments you can deploy and how to schedule them. Then, you’ll create an experiment that will inject network failures into the example Hello Kubernetes services, deployed as part of prerequisites.
Chaos experiments order ChaosMesh which area of the cluster or running application to disrupt, simulating a real failure. Common failures at the cluster level include pod (PodChaos), network (NetworkChaos) and DNS (DNSChaos) faults. ChaosMesh can also inject faults on the pod level, such as making the running kernel panic (KernelChaos) or the underlying storage drive delayed or unavailable (BlockChaos).
While outside of the scope for this tutorial, ChaosMesh can also be used to induce failures in physical machine environments. Similarly, it can inject faults into processes, networks and can even take over physical machines and shut them down, simulating a power loss.
Injecting NetworkChaos
Since the Hello Kubernetes applications you deployed as part of the prerequisites are web based, the chaos experiment you’ll now create will simulate a network fault that corrupts the requests. You’ll store it in a file named network-corruption.yaml. Create and open it for editing with the following command:
-
- nano network-corruption.yaml
-
Add the following lines, defining a NetworkChaos experiment:
[label network-corruption.yaml]
kind: NetworkChaos
apiVersion: chaos-mesh.org/v1alpha1
metadata:
namespace: default
name: network-corruption
spec:
selector:
namespaces:
- default
labelSelectors:
app: hello-kubernetes-first
mode: all
action: corrupt
corrupt:
corrupt: '60'
direction: to
To select which pods should be affected by the experiment, you specify the hello-kubernetes-first label in the default namespace, as part of the selector parameter. The action that should be applied to the network requests is to corrupt, but only 60% of the time as specified in the corrupt section of the spec. The direction defines that requests from the pod to the outside (to) should be damaged.
When you’re done, save and close the file. Apply it by running:
-
- kubectl apply -f network-corruption.yaml
-
The output will be:
[secondary_label Output]
networkchaos.chaos-mesh.org/network-corruption created
Next, navigate to the domain name at which you exposed the first Hello Kubernetes application (referred in the prerequisite tutorial as hw1.your_domain). You will notice that the page may be partially unavailable and take a while to load, thanks to the high percentage of corruption (60%).
However, running an experiment continually is not always preferable. As the user experience is now severely degraded, pause the experiment by running:
-
- kubectl annotate networkchaos network-corruption experiment.chaos-mesh.org/pause=true --overwrite
-
You’ll see the following output:
[secondary_label Output]
networkchaos.chaos-mesh.org/network-corruption annotated
ChaosMesh honors the experiment.chaos-mesh.org/pause annotation immediately and disables the experiment. Navigate to your browser again and try reloading the page to confirm that it loads normally.
Scheduling experiments
To schedule when and for how long the experiment runs, you’ll define a Schedule in a separate file called network-corruption-schedule.yaml. Open it for editing:
-
- nano network-corruption-schedule.yaml
-
Add the following definition:
[label network-corruption-schedule.yaml]
apiVersion: chaos-mesh.org/v1alpha1
kind: Schedule
metadata:
name: network-corruption-schedule
spec:
schedule: '* * * * *'
historyLimit: 2
type: 'NetworkChaos'
networkChaos:
action: corrupt
mode: all
selector:
namespaces:
- default
labelSelectors:
app: hello-kubernetes-first
corrupt:
corrupt: '60'
correlation: '0'
direction: to
duration: '10s'
The Schedule accepts a cron definition in the schedule field, which controls when the experiment should run. The value you provide (* * * * *) denotes every minute.
The experiment’s type is set as NetworkChaos and the scheduled experiment itself is now defined under a section called networkChaos. A parameter that wasn’t present before is duration, which is set to 10s. This means that the experiment will last for ten seconds each time it’s run. Because the historyLimit is set to 2, ChaosMesh will ensure that manifests of the last two experiments remain present in the cluster for later retrieval.
Save and close the file, then apply by running:
-
- kubectl apply -f network-corruption-schedule.yaml
-
The output will be:
[secondary_label Output]
schedule.chaos-mesh.org/network-corruption-schedule created
Run the following command to watch over the available NetworkChaos objects in your cluster:
-
- kubectl get networkchaos -w
-
At the start of every minute, you’ll see a new chaos experiment being created:
[secondary_label Output]
NAME ACTION DURATION
network-corruption-schedule-q7dbs corrupt 10s
network-corruption-schedule-q7dbs corrupt 10s
...
As specified, these experiments will corrupt network traffic and last exactly ten seconds. Some of the shown entries might be repeated as ChaosMesh updates them.
Navigate to your domain and try refreshing your domain. Notice that the page will slowly load (or fail to) in the first ten seconds of each minute of wall clock time.
After a few minutes, list the NetworkChaos objects in the cluster:
-
- kubectl get networkchaos
-
Because you set the historyLimit parameter in the Schedule to 2, you’ll see at most two experiments created by the schedule remaining in your cluster:
[secondary_label Output]
NAME ACTION DURATION
network-corruption corrupt
network-corruption-schedule-6hn6p corrupt 10s
network-corruption-schedule-rc4nx corrupt 10s
In this section, you’ve learned about the different types of chaos experiments that ChaosMesh provides. You’ve defined a NetworkChaos, corrupting the traffic from one of the Hello Kubernetes applications you’ve already deployed. Then, you’ve deployed a Schedule to automatically run the chaos experiment every minute. In the next step, you’ll expose the ChaosMesh dashboard at your domain.
Step 3: Exposing ChaosMesh Dashboard and Enabling Persistence
In this step, you’ll expose the ChaosMesh dashboard at your domain by creating an Ingress. You’ll also make it persist experiments and other data by modifying the Helm chart.
The dashboard allows you to watch over and create chaos experiments through a web based interface. To expose it at your domain, you’ll need to create an Ingress for the chaos-dashboard service. The Helm chart you’ve used to deploy ChaosMesh in Step 1 can deploy one if configured to do so. Open values.yaml for editing:
-
- nano values.yaml
-
Add the following lines to the end of the file:
[label values.yaml]
chaosDaemon:
runtime: containerd
socketPath: /run/containerd/containerd.sock
dashboard:
ingress:
enabled: true
ingressClassName: nginx
hosts:
- name: dashboard.your_domain
persistentVolume:
enabled: true
First, you enable the Ingress creation, set Nginx as the Ingress controller and define a hostname where the dashboard will be exposed. Then, you enable the creation of a PersistentVolume, which will hold the dashboard data. By default, the dashboard stores data in an SQLite database.
Remember to replace dashboard.your_domain with your domain name, then save and close the file.
To apply the new values, upgrade the Helm release by running:
-
- helm upgrade chaos-mesh chaos-mesh/chaos-mesh -n=chaos-mesh -f values.yaml
-
You’ll see the following output:
[secondary_label Output]
Release "chaos-mesh" has been upgraded. Happy Helming!
NAME: chaos-mesh
LAST DEPLOYED: Sun Nov 5 14:12:59 2023
NAMESPACE: chaos-mesh
STATUS: deployed
REVISION: 2
TEST SUITE: None
NOTES:
...
The revision count is now 2, indicating that the release was upgraded.
The pod for the dashboard is now being provisioned. You can track the progress by running:
-
- kubectl get pods -n chaos-mesh -w
-
As part of the prerequisites, you have configured your domain name to point to the Load Balancer used by the Nginx Ingress. You can now navigate to your domain name in your browser. The dashboard should load and ask for a token:
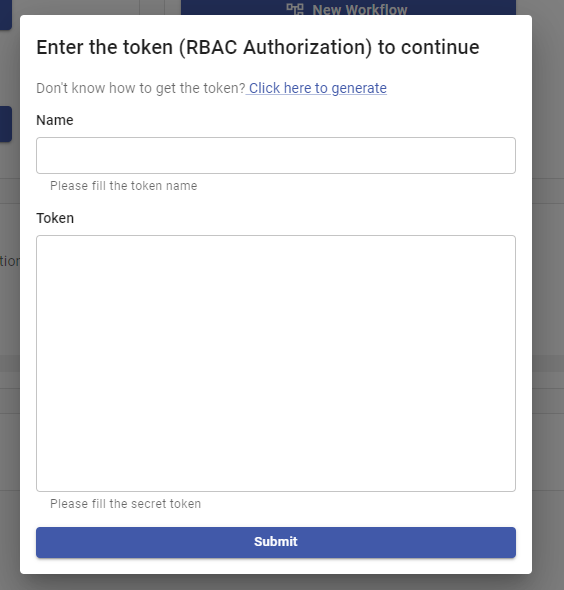
Here, the requested token is a credential tied to a ServiceAccount. A ServiceAccount is a non-human identity in the cluster with specific permissions, detailing what actions it can perform. The dashboard requires it to interact with the cluster.
You’ll store the ServiceAccount and related definitions in a file called dashboard-rbac.yaml. Create and open it for editing:
-
- nano dashboard-rbac.yaml
-
Add the following lines:
[label dashboard-rbac.yaml]
kind: ServiceAccount
apiVersion: v1
metadata:
namespace: default
name: account-cluster-manager-dashboard
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: role-cluster-manager-dashboard
rules:
- apiGroups: [""]
resources: ["pods", "namespaces"]
verbs: ["get", "watch", "list"]
- apiGroups: ["chaos-mesh.org"]
resources: [ "*" ]
verbs: ["get", "list", "watch", "create", "delete", "patch", "update"]
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: bind-cluster-manager-dashboard
subjects:
- kind: ServiceAccount
name: account-cluster-manager-dashboard
namespace: default
roleRef:
kind: ClusterRole
name: role-cluster-manager-dashboard
apiGroup: rbac.authorization.k8s.io
This manifest will create three objects: a ServiceAccount that the dashboard will use, a ClusterRole that defines what actions it can perform cluster-wide and a RoleBinding, which applies the ClusterRole to the ServiceAccount. In addition, the ClusterRole specifies that the dashboard will have full access to ChaosMesh.
When you’re done, save and close the file. Then, apply it by running:
-
- kubectl apply -f dashboard-rbac.yaml
-
The output will be:
[secondary_label Output]
serviceaccount/account-cluster-manager-dashboard created
clusterrole.rbac.authorization.k8s.io/role-cluster-manager-dashboard created
clusterrolebinding.rbac.authorization.k8s.io/bind-cluster-manager-dashboard created
You can now create a token for the ServiceAccount
-
- kubectl create token account-cluster-manager-dashboard
-
The output will be your token:
[secondary_label Output]
eyJhbGciOiJSUzI1NiIsImtpZCI6IlZiai16RGt5Q0FTWHExNmxlTW1KQ2JIWFcwdDBfRXJMc05oMElVYm9jaEki
...
Navigate back to the dashboard and input a name for your token along with its value, then press Submit to log in. You should see the dashboard:
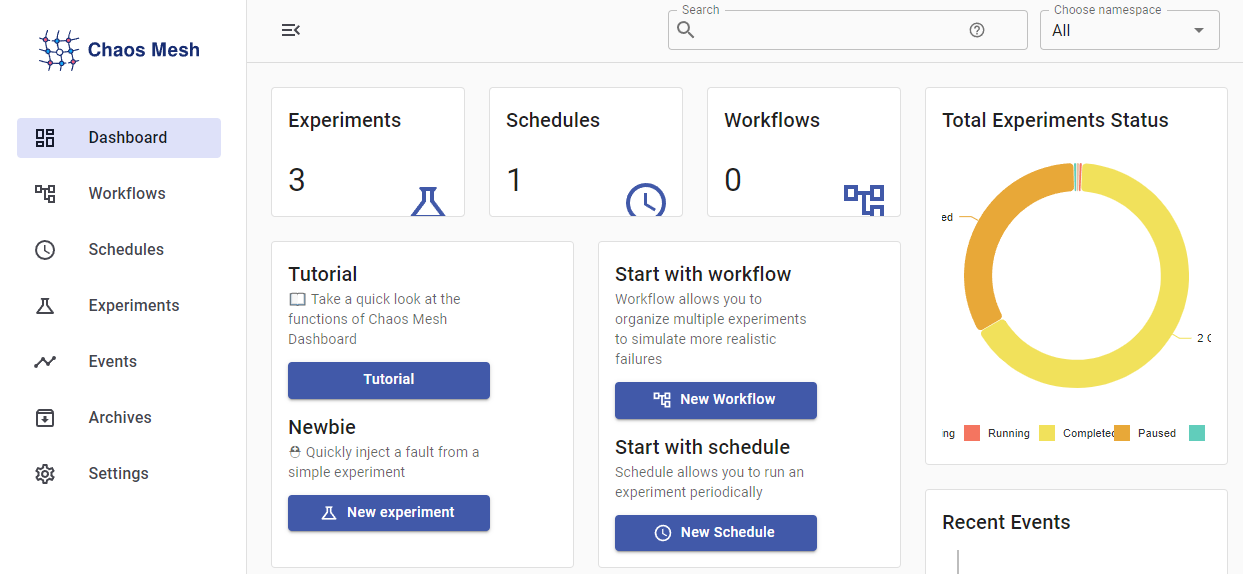
In this section, you’ve exposed the dashboard by configuring the Helm chart to deploy an Ingress, exposed at your domain. You’ve also enabled data persistence, meaning that the database the dashboard creates will be preserved in a PersistentVolume. Now that you’ve created a token and logged in, you’ll explore the dashboard and learn how to manage experiments.
Step 4: Defining and Running a Chaos Experiment Using the Dashboard
In this step, you’ll learn how to navigate in the ChaosMesh web interface. Then, you’ll create, watch over and archive an experiment using the dashboard.
The dashboard offers the sections listed in the menu on the left. The first section, titled Dashboard, is the default upon login and provides you with a on-the-glance view of ChaosMesh processes in the cluster. You should see that there are two active experiments and a Schedule, which you deployed in the previous steps.
Before creating an experiment, you’ll first pause the running Schedule. To list them, press on Schedules from the menu. You’ll see the network-corruption-schedule listed as running:

To pause the schedule, press the first button on the right, then press Confirm when prompted. You’ll see the new status reflected immediately:
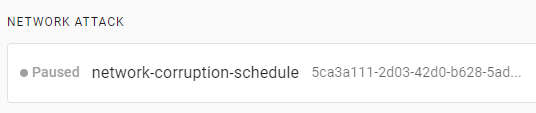
You can also archive the Schedule using the second button on the right. Archiving a Schedule will pause and move it to the Archives section for later retrieval.
To look over currently deployed experiments, press on Experiments from the menu. Both network corruption experiments, created by the Schedule, should now be paused:

To create a new experiment, press on New experiment. First, you’ll be prompted to select the type of experiment:
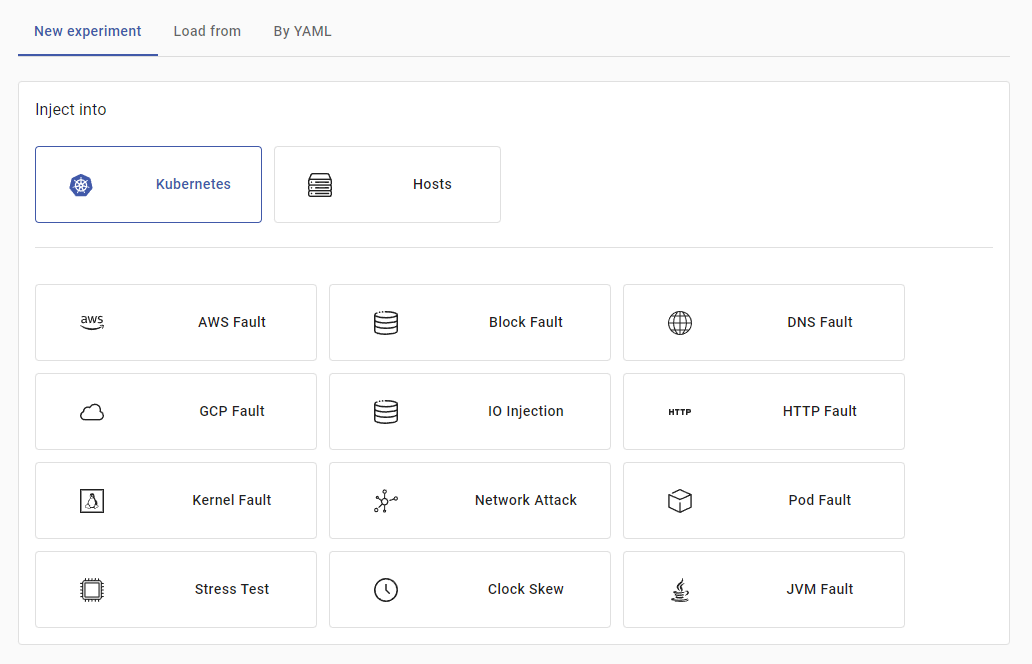
Press on Network Attack to select it. The dashboard will now allow you to select the experiment action. Choose Corrupt and input 60 as the corruption percentage, as shown:
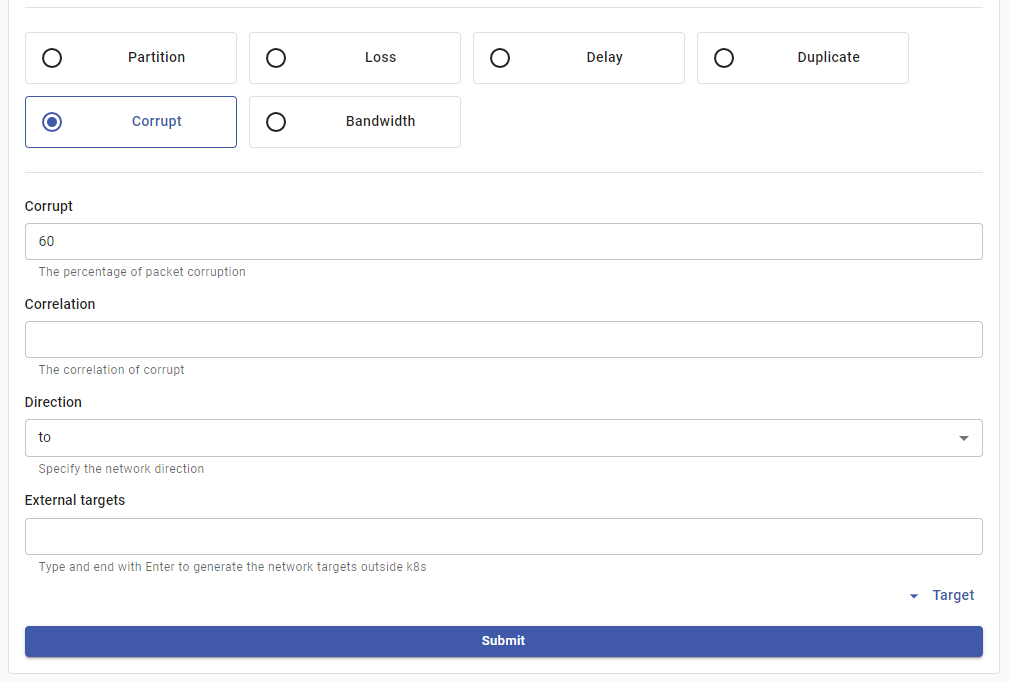
The parameters shown are the same ones that you can set in a YAML definition of NetworkChaos. When you’re done, press Submit as you’ve configured the nature of the attack.
The next section, Experiment Info, allows you to configure the scope of the experiment. The dashboard retrieved the namespaces and labels from the cluster and will offer to fill the input fields for you. This time, you’ll induce chaos into the second Hello Kubernetes deployment. Like the first, it resides in the default namespace, but its label selector is hello-kubernetes-second.
All relevant Pods will be automatically checked. Input a name for the experiment under Metadata, such as network-chaos-second and press on Run continuously. The section should look similarly to this:
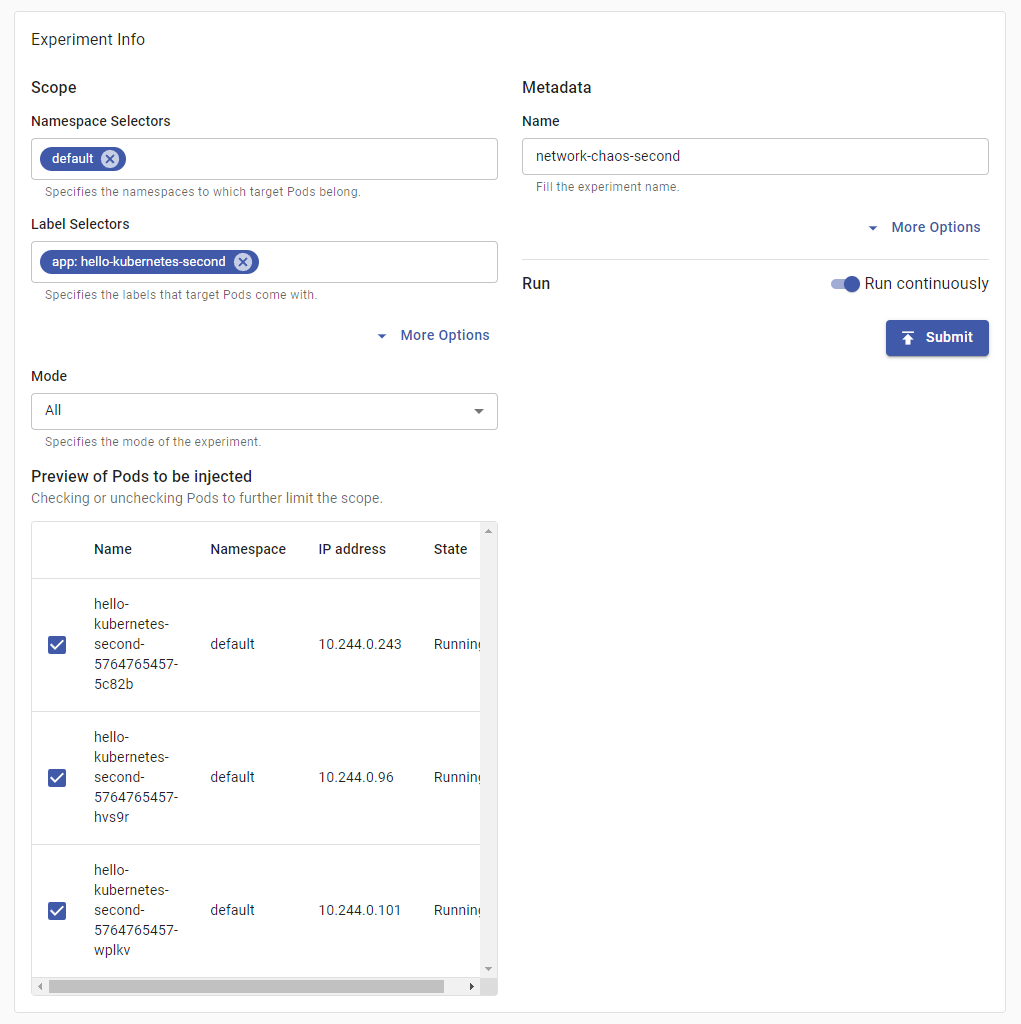
When you’re done, press on Submit. The dashboard will confirm that all needed info is available, so press on Submit once again:
You’ll be redirected to Experiments. The experiment you just created should be injecting itself:

After a few moments, its state should turn to Running:

In your browser, navigate to the domain of your second Hello Kubernetes deployment. You should notice that the page is slow and takes a while to load, meaning that the experiment you just created is running as configured.
To see more information about the experiment, press on it. You’ll see interface similar to following:
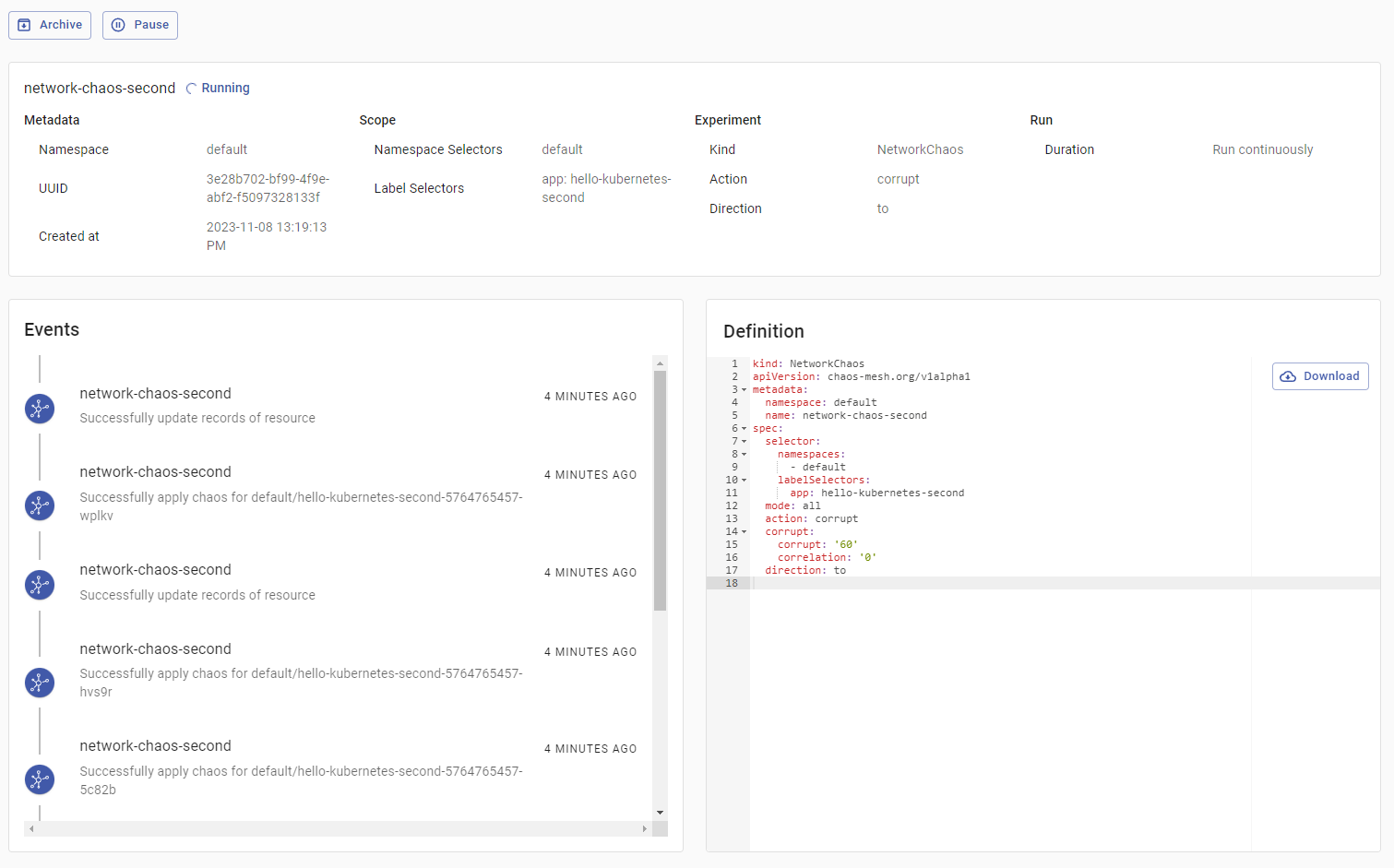
The dashboard offers you to Archive or Pause the experiment using the buttons on the top left. Detailed specifications, such as the namespace, name and type of the experiment are shown in the Metadata section. Events lists the actions ChaosMesh took to inject the experiment, and their outcome. This section will also show errors that occurred during the lifetime of the experiment. Lastly, you can inspect the YAML definition of the experiment under Definition.
Archive the experiment by pressing on Archive and confirming. The experiment will be deleted and removed from the list:
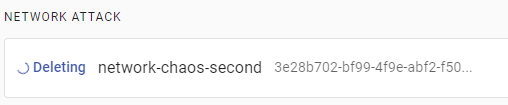
To retrieve it, press on Archives in the menu, then on the Experiments tab. You’ll see that your experiment is saved:
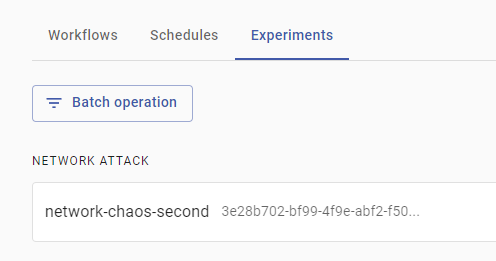
In this section, you’ve learned how to use create, pause and watch over chaos experiments in the dashboard. You’ve also seen how to archive an experiment for later retrieval. You’ll now learn how to create a chaos workflow using the command line.
Step 5: Defining and Running a Chaos Workflow Using kubectl
In this step, you’ll deploy a chaos workflow to your cluster using kubectl. You’ll also utilize a health check, aborting the workflow if the tested resources become unavailable.
Till now, you’ve deployed and controlled chaos experiments as standalone entities. ChaosMesh allows you to deploy multiple experiments at once using chaos workflows.
A workflow consists of multiple ChaosMesh objects with their definitions. The workflow you’ll deploy consists of a StatusCheck and a NetworkChaos. While the NetworkChaos will add a bit of latency, StatusCheck will continuously monitor the availability of the Hello Kubernetes deployment that is being tested.
You’ll store the workflow in a file named networkchaos-statuscheck-workflow.yaml. Create and open it for editing by running:
-
- nano networkchaos-statuscheck-workflow.yaml
-
Add the following lines:
[label networkchaos-statuscheck-workflow.yaml]
apiVersion: chaos-mesh.org/v1alpha1
kind: Workflow
metadata:
name: networkchaos-statuscheck-workflow
spec:
entry: the-entry
templates:
- name: the-entry
templateType: Parallel
deadline: 120s
children:
- workflow-status-check
- workflow-network-chaos
- name: workflow-status-check
templateType: StatusCheck
deadline: 120s
abortWithStatusCheck: true
statusCheck:
mode: Continuous
type: HTTP
intervalSeconds: 3
failureThreshold: 2
http:
url: https://hw2.your_domain
method: GET
criteria:
statusCode: "200"
- name: workflow-network-chaos
templateType: NetworkChaos
deadline: 120s
networkChaos:
direction: to
action: delay
mode: all
selector:
labelSelectors:
"app": "hello-kubernetes-second"
delay:
latency: "9000ms"
The main part of a Workflow definition is are the three entries in templates. The first one (the-entry) enumerates the workflow actions in children (the StatusCheck and NetworkChaos, respectively) and allows them to run in Parallel with a timeout of 120s, limiting the time the workflow is active.
The StatusCheck is configured to poll the given URL through HTTP every 3 seconds (as set in intervalSeconds), expecting a 200 status code. The health check should be considered failing after 2 unsuccessful tries (failureThreshold). To stop the workflow execution if the health check fails, you set the abortWithStatusCheck parameter to true.
The third definition in templates is for NetworkChaos, similar as in the previous steps. However, instead of corrupting the traffic to the first Hello Kubernetes deployment, here the action is set to delay with an additional parameter: latency, defining for how long to delay a request. Here, it’s set to a very high value of 9000ms (nine seconds) to demonstrate the recovery mechanisms of ChaosMesh.
Save and close the file when you’re done.
Deploy the workflow by running:
-
- kubectl apply -f networkchaos-statuscheck-workflow.yaml
-
The output will be:
[secondary_label Output]
workflow.chaos-mesh.org/networkchaos-statuscheck-workflow created
To list the available workflows, run:
-
- kubectl get workflow
-
You’ll see the one you just applied:
[secondary_label Output]
NAME AGE
networkchaos-statuscheck-workflow 2s
You can also list the entries related to a workflow (the declarations under templates):
-
- kubectl get workflownode --selector="chaos-mesh.org/workflow=networkchaos-statuscheck-workflow"
-
kubectl will output the three you deployed:
[secondary_label Output]
NAME AGE
the-entry-tsj9w 20s
workflow-network-chaos-8tpp4 20s
workflow-status-check-xs4c2 20s
The dashboard will show that both experiments are running at the same time:
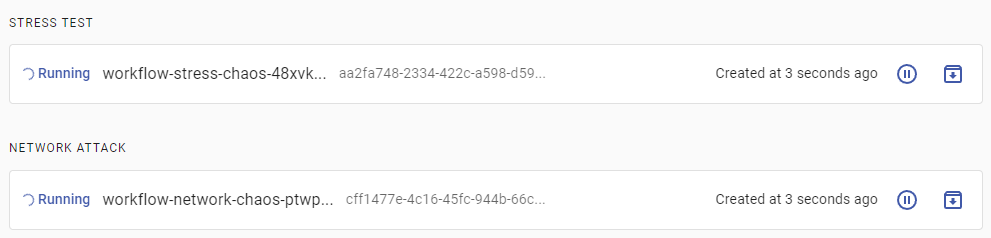
Because you set a very high latency value of nine seconds, the StatusCheck will fail early on and abort the Workflow. To check what the workflow did, look at the events of the the-entry by running:
-
- kubectl describe workflownode the-entry-tsj9w
-
You’ll see the logged events near the end of the output:
[secondary_label Output]
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodesCreated 2m17s workflow-parallel-node-reconciler child nodes created, workflow-status-check-xs4c2,workflow-network-chaos-8tpp4
Normal WorkflowAborted 2m7s workflow-abort-workflow-reconciler abort the node because workflow networkchaos-statuscheck-workflow aborted
The StatusCheck failed and because you set abortWithStatusCheck to true, ChaosMesh also aborted the whole Workflow, deleting the NetworkChaos experiment.
You’ll now set the latency value of the NetworkChaos to a much smaller value and re-run the Workflow. Open the file for editing:
-
- nano networkchaos-statuscheck-workflow.yaml
-
Near the end of the file, set the experiment latency to 90ms:
[label networkchaos-statuscheck-workflow.yaml]
...
- name: workflow-network-chaos
templateType: NetworkChaos
deadline: 120s
networkChaos:
direction: to
action: delay
mode: all
selector:
labelSelectors:
"app": "hello-kubernetes-second"
delay:
latency: "90ms"
Save and close the file. To re-run the Workflow, delete it from the cluster first:
-
- kubectl delete -f networkchaos-statuscheck-workflow.yaml
-
Then, apply it again with the new values by running:
-
- kubectl apply -f networkchaos-statuscheck-workflow.yaml
-
After two minutes, which you specified as the deadline, the Workflow will stop. To check the Workflow logs, run the following command:
-
- kubectl describe workflow networkchaos-statuscheck-workflow
-
Looking at events near the end of the output, you’ll see that the Workflow has completed successfully:
[secondary_label Output]
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal EntryCreated 5m36s workflow-entry-reconciler entry node created, entry node the-entry-f9mkl
Normal WorkflowAccomplished 2m16s workflow-entry-reconciler workflow accomplished
In this section, you have learned about chaos workflows as a way to couple multiple experiments together with a health check, aborting the process if the user experience becomes impacted.
Step 6: (Optional) Uninstalling ChaosMesh Using Helm
In this step, you’ll delete all chaos experiments and uninstall ChaosMesh from your cluster.
Before uninstalling ChaosMesh, all experiments, schedules and workflows must be deleted from the cluster. For the resources deployed as part of this tutorial, you can achieve that by running:
-
- kubectl delete networkchaos,schedule,workflow,workflownode --all
-
Next, uninstall the Helm release:
-
- helm uninstall chaos-mesh -n chaos-mesh
-
You’ll see the following output:
[secondary_label Output]
release "chaos-mesh" uninstalled
Finally, uninstall the Custom Resource Definitions (CRDs) that Helm leaves behind by running:
-
- kubectl delete crd $(kubectl get crd | grep 'chaos-mesh.org' | awk '{print $1}')
-
This command will enumerate every CRD related to ChaosMesh and pipe it into the command for deletion. The output will be similar to this:
[secondary_label Output]
customresourcedefinition.apiextensions.k8s.io "awschaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "azurechaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "blockchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "dnschaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "gcpchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "httpchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "iochaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "jvmchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "kernelchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "networkchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "physicalmachinechaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "physicalmachines.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "podchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "podhttpchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "podiochaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "podnetworkchaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "remoteclusters.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "schedules.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "statuschecks.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "stresschaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "timechaos.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "workflownodes.chaos-mesh.org" deleted
customresourcedefinition.apiextensions.k8s.io "workflows.chaos-mesh.org" deleted
ChaosMesh and its resource definitions are now purged from your cluster.
Conclusion
ChaosMesh works in the background and helps you and your organization discover possible failure points ahead of time by replicating real-world faults and delays. It’s native to Kubernetes and carries a breadth of ways to inject chaos into a running cluster. It also provides a web based user interface through the ChaosMesh dashboard, simplifying experiment management and creation.
For more information and resources about ChaosMesh, please visit the official docs.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
author
This textbox defaults to using Markdown to format your answer.
You can type !ref in this text area to quickly search our full set of tutorials, documentation & marketplace offerings and insert the link!

Join the Tech Talk

Hollie's Hub for Good
Working on improving health and education, reducing inequality, and spurring economic growth? We’d like to help.

